Post Mortem: App Store Outage on January 24th, 2020
A breakdown of the outage and steps we're taking at RevenueCat to respond better next time.




This past Friday, January the 24th, the App Store had perhaps its biggest incident ever. For roughly 5 hours, developers were unable to verify receipts via the verifyReceipt endpoint. This meant that app users were able to complete in-app purchases, but content was never unlocked because developers couldn’t validate the purchase independently. By our own estimates, this caused upwards of half a million failed purchases on the App Store. These failed purchases resulted in countless tickets, bad App Store reviews, and thousands of lost hours ($$$) for developers.
By our own estimates, this caused upwards of a half a million failed purchases on the App Store
Our goal at RevenueCat is to handle these sorts of issues so developers can focus on their customers and not payments. We were monitoring the situation all along, and we did take efforts to mitigate the issue. However, there were things that caught us off guard, and things we could have done better. Whenever we have an incident internally, we always write up a “post mortem”, a small technical assessment of the facts, and a discussion of how we can improve or prevent the issue moving forward.
We’d like to share our post mortem for this incident with the broader community so developers can better understand what happened. We’d also like to share some of the things we can do to improve how we responded to the incident.
Timeline
4:11AM PST – The App Store verifyReceipt endpoint begins failing and timing out intermittently. About 45% of requests were failing with 50x errors.
6:20AM PST – The failure mode for the verifyReceipt endpoint changed from intermittent 500s to 200 (OK) but returning an unusable response, in this case a webpage trying to redirect to iTunes.
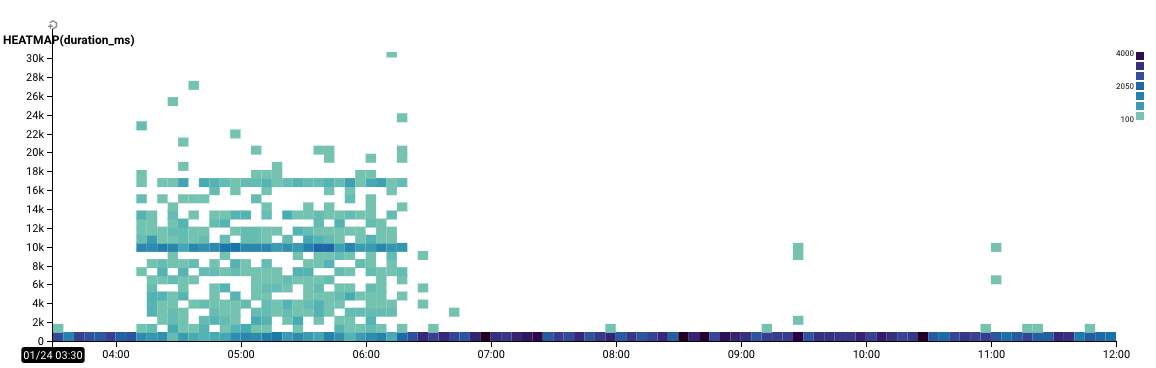
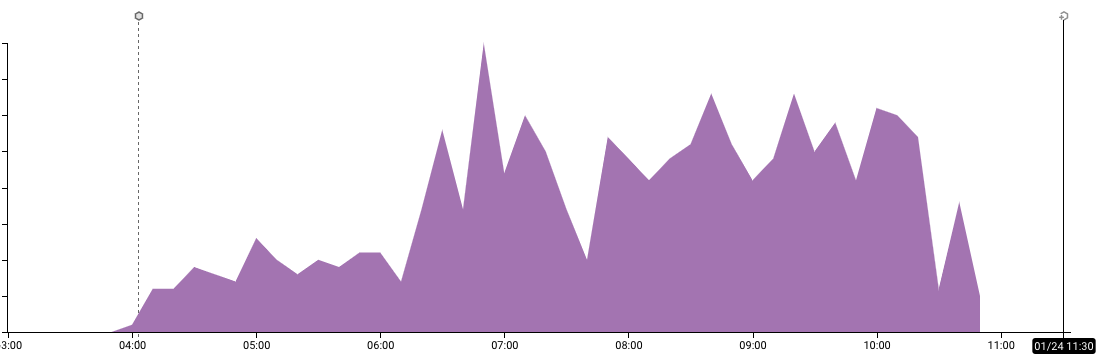
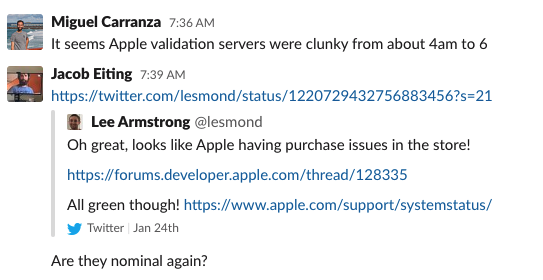
7:36 AM PST – Jacob and Miguel independently discover the issue, from Twitter and our own monitoring respectively.
8:05 AM PST – Miguel realizes the scope of the issue, i.e. that the endpoint was down completely since 6:22AM.

8:12 AM PST – We post the alert to our Twitter and start monitoring the situation fully.
8:39 AM PST – After getting a better understanding of what exactly was happening, we start working on code to leverage our entitlements system to temporarily unlock access for anyone who posts a receipt. We didn’t have this code ready to go so started working on it.

10:20 AM PST – We deploy our server side hack to enable temporary entitlements.

10:55 AM PST – The verifyReceipt endpoint begins functioning again.
12:57 PM PST – Using our own server logs, we start re-sending receipts that Apple wasn’t able to validate during the outage.
2:27 PM PST – We complete replaying receipts for new purchases that happened during the outage, restoring access for any users that purchased before our mitigation was deployed.
8:47 PM PST – We completed re-importing all receipts, including renewals. We closed out the issue on our status page.
Takeaways
Two big things on our side hindered the way we responded to this incident. The first is reporting and detection, the second in the mitigation.
Most of the RevenueCat team is located in PST, so it wasn’t until after 7AM that we were doing our morning scroll and discovered something was wrong. The data was there in our monitoring, but it wasn’t set up to notify anyone. We use OpsGenie for on-call rotation, and have the ability to easily trigger alerts that will go to the on-call persons phone, and if it doesn’t get an answer in 5 minutes, calls the entire server team. We should have been notified as soon as our receipt endpoint had elevated 500s. Most of our incidents up to this point have been caused by performance issues that cause our response time to spike and that’s what most of monitoring is configured around.
The second issue was not having a mitigation technique in place. We’ve seen this issue once before, in the summer of 2018 for about 45 minutes. There are cases where the verifyReceipt endpoint will just fail, and this actually happens several times per day. We do 1 retry server side, as well as retries in the SDK, and that usually resolves it in normal operations, but this was different. We were able to deploy a mitigation, but it only solved the problem for users who rely on our entitlements system, and it took us 6 hours from incident start to get it deployed.
Action Items
- Use Honeycomb to set up alerts for anomalous error codes so that the on-call person is alerted as soon as things begin to fail.
- Implement our own receipt validation to fall back on when Apple returns a 500. This will allow us to track almost everything with 100% fidelity as opposed to using temporary entitlements to patch over the issue.
Conclusion
While I think we did a good job of reacting to the outage, there are a number of improvements to the code and our internal processes that will make the next incident less impactful for RevenueCat customers. Over 1000 apps trust RevenueCat with their in-app purchase stack, and we take that seriously. We want to make in-app purchase code something developers don’t need to think about. To achieve this goal we’ll continue to invest in our reliability and incident response.
You might also like
- Blog post
RevenueCat Paywalls: Now even more flexible with v2
A new editor, more flexibility, and full control over your paywall’s design.
- Blog post
Implementing in-app purchases and monetizing your Roku app: A step-by-step guide
A comprehensive guide to implementing and monetizing your Roku channel, from choosing the right strategy to technical tips and integration best practices.
- Blog post
How we built the RevenueCat SDK for Kotlin Multiplatform
Explore the architecture and key decisions behind building the RevenueCat Kotlin Multiplatform SDK, designed to streamline in-app purchases across platforms.
